이 글은 구글의 머신 러닝 단기 집중 과정을 참고로 작성하였습니다.
(ML 문제로 표현하기, ML로 전환하기, 손실 줄이기)
링크 : https://developers.google.com/machine-learning/crash-course?hl=ko
머신 러닝 개요
머신 러닝 : 입력을 결합하여 새로운 데이터를 예측하는 방법을 기계가 학습하는 것을 의미합니다.
라벨(Label) : 예측하고자 하는 항목
예시) 사진에 표시된 동물의 종류(고양이, 강아지 등)
특성(Attribute) : 예측에 사용할 입력 변수
예시) 스팸 메일 감지할 때 사용할 수 있는 변수
이메일 텍스트 단어, 보내는 사람의 주소, 이메일 전송 시간
예(Instance) :
1. 라벨이 있는 Instance - 모델을 학습 시킬 때 쓰이는 Instance
| 평균 연령 | 방 수 | 화장실 수 | 집 가격(라벨) |
| 35 | 5 | 1 | 2억원 |
| 25 | 3 | 3 | 6억원 |
| 42 | 4 | 2 | 4억원 |
집 가격을 예측하는 모델을 만들기 위해선 집 가격이 있는 Instance를 활용해야 합니다.
2. 라벨이 없는 Instance
| 평균 연령 | 방 수 | 화장실 수 |
| 27 | 2 | 2 |
| 38 | 6 | 5 |
| 51 | 4 | 3 |
집 가격이 없는 Instance 이기 때문에 집 가격을 예측하는 모델을 학습시킬 수 없습니다.
모델(Model) : 특성과 라벨의 관계를 정의합니다. 학습을 통해 모델을 만들고 만든 모델을 이용해 라벨 값을 추론할 수 있습니다.
-
회귀(Regression) 모델 : 연속적인 값을 예측하는 모델입니다.
예시 - 캘리포니아 주택 가격 예측 -
분류(Classification) 모델 : 불연속적인 값을 예측하는 모델입니다.
예시 - 스팸 메일 인지 아닌지 예측
- 회귀 모델에서 회귀(Regression)의 뜻은 무엇일까요?
회귀란 A에서 B로 돌아간다는 뜻입니다. 머신 러닝에서의 회귀 모델은
예측값의 평균이 실제값의 평균으로 돌아가는 것을 의미합니다.
오차의 측면에서 본다면 오차의 평균이 0으로 돌아가는 것을 의미합니다.
선형 회귀(Linear Regression)
머신 러닝에 사용되는 모델은 여러가지가 있습니다. 그 중 선형 회귀(Linear Regression) 모델에 대해 알아보겠습니다.
섭씨 온도와 귀뚜라미가 1분당 우는 횟수에 대한 데이터베이스를 받았습니다. 이 데이터베이스로 가장 먼저 해야할 것은 섭씨 온도와 귀뚜라미가 1분당 우는 횟수의 그래프를 만들어 검토하는 것입니다.

그래프를 만들고나면 섭씨 온도와 귀뚜라미가 1분당 우는 횟수가 선형 관계임을 알 수 있습니다.

이 선을 대수학적으로 y=mx+b로 표현할 수 있습니다. 머신 러닝의 용어로 이 수식은 다음을 의미합니다.
Y는 섭씨 온도, 예측하려는 값인 라벨입니다.
M은 선의 기울기입니다.
X는 1분당 우는 횟수, 입력 특성 값 입니다.
B는 y절편으로 bias에 해당합니다.
머신 러닝에서는 여러가지 특성을 사용하여 더 정교한 모델을 만들 수 있습니다. 이 경우 방정식은 다음과 같습니다.

학습 및 손실
Instance에서 라벨을 예측하는 모델은 여러가지 일 수 있습니다. 가장 예측을 잘하는 모델을 만드는 것이 개발자의 목표입니다. 어떻게 더 좋은 모델을 만들 수 있을까요? 머신 러닝에서는 손실을 계산하는 학습을 통해 모델을 발전시킵니다.
학습이란 라벨이 있는 데이터로부터 가중치와 편향값을 변경하는 것을 의미합니다. 이 학습을 통해 우리가 위에서 봤던 방정식의 w와 b값들이 바뀌게 됩니다.
손실이란 모델의 예측이 얼마나 잘못되었는지를 나타내는 수치입니다. 예측을 잘 할수록 손실 값을 줄어들고, 예측을 못 할수록 손실 값은 증가합니다. 이 값을 통해 우리가 만든 모델이 얼마나 좋은 모델인지 알 수 있습니다.

빨간색 화살표는 손실, 파란색 직선은 예측을 나타냅니다. 위의 예시에서 손실은 왼쪽 모델이 더 크기 때문에 오른쪽 모델이 더 예측을 잘하는 모델입니다.
앞서 손실은 모델이 예측을 얼마나 잘못했는지에 대한 수치라고 하였습니다. 위의 예시에서 손실을 어떻게 수치화할 수 있을까요? 쉽게 생각하면 빨간색 화살표의 값을 모두 합한 것을 손실로 계산할 수 있습니다.
머신 러닝에서 많이 쓰이는 손실 계산 방법으로는 제곱 손실이 있습니다. 이는 (y-y')^2으로 실제값과 예측값의 차이를 제곱한 것을 의미합니다. 모든 제곱 손실 값의 평균을 평균 제곱 오차(MSE) 라고 합니다.


위의 예시에서 MSE가 높은 모델은 무엇일까요? 정답은 오른쪽 모델입니다.


손실 줄이기
어떻게 하면 손실을 줄여서 더 좋은 모델을 얻을 수 있을까요? 머신 러닝에서는 학습을 반복하는 방법을 사용합니다. {가중치와 편향을 임의의 값으로 설정하고 예측을 합니다. 손실을 계산합니다. 손실이 줄어들도록 가중치와 편향을 변경합니다.} 이 과정을 반복하며 손실을 줄이다가 손실이 매우 느리게 변할 때 학습을 멈춥니다. 이를 모델이 수렴했다고 합니다.
손실을 줄이는 방향으로 매개 변수(가중치와 편향)를 어떻게 변경할 수 있을까요? 경사하강법을 사용할 수 있습니다.

MSE를 다시 한번 살펴 보겠습니다. Prediction(x)는 y=mx+b의 형태입니다. 따라서 MSE는 w에 대한 2차식 형태임을 알 수 있습니다. 이를 그래프로 그리면 다음과 같습니다.

손실은 2차 함수이기 때문에 극소값이 항상 존재합니다. 이 극소값이 손실의 최소값이 됩니다. 손실이 최소값이 되는 w를 찾는 것이 우리의 목표입니다. 경사하강법은 이 w 값을 찾기 위해 다음의 방법을 사용합니다.

임의의 시작점을 잡습니다(w값을 임의로 정합니다). 우리는 손실 함수의 시작점에서 편미분 값을 알 수 있습니다.

시작점에서 편미분 값이 음수입니다. 그래서 w를 증가하는 방향으로 다음 지점의 값을 정합니다. 이런 식으로 다음 지점을 정하는 것을 반복하면 손실이 최소가 되는 지점에 도달할 수 있습니다. 다음 지점으로 갈 때 얼마만큼 이동할지 유저가 직접 정할 수 있습니다. 이를 학습률이라고 합니다. 유저가 직접 정할 수 있는 값들을 초매개변수(Hyper Parameter)라고 부릅니다. 올바른 학습을 하기 위해선 학습률 값을 잘 지정해야 합니다.

학습률이 너무 작다면 학습 시간이 너무 오래 걸립니다.

학습률이 너무 크다면 최소값을 찾을 수 없게됩니다.

학습률이 적절할 때 학습 시간을 줄이면서 효율적으로 좋은 모델을 찾을 수 있습니다.
경사하강법에서 배치의 크기를 전체 데이터 세트로 하였을 때는 학습하는데 너무 많은 시간이 소요될 수 있습니다. 머신 러닝에서 데이터 세트는 많게는 수십억에서 수천억개의 예가 포함되어있을 수 있습니다. 이 경우 배치 사이즈가 너무 클 경우 오래걸릴 수 있습니다.
이를 보완하는 방법이 확률적 경사하강법(SGD)입니다. SGD에서는 배치 크기를 1로 설정합니다. 확률적이란 의미는 하나의 예가 무작위로 선택된다는 것을 의미합니다.
미니 배치 확률적 경사하강법은 전체 배치 반복과 SGD의 절충입니다. 배치 크기는 10~1000개 사이로 설정하면서 무작위로 예시를 선택합니다.
경사하강법을 사용하지 않고 방정식을 미분하여 최소값을 찾으면 안될까?

손실이 최소가 되는 과정을 다시 살펴봅시다. 손실 함수는 w에 대한 2차 함수이기 때문에 굳이 경사하강법으로 손실을 줄이는 방향으로 반복할 필요 없이, w에 대해 미분하여 극소값을 찾으면 가장 빠르게 손실이 최소가 되는 w값을 찾을 수 있지 않을까요?
이는 w가 한 개일 때만 가능합니다.
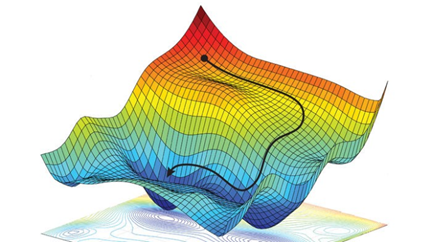
가중치가 여러 개일 때의 그래프는 위와 같습니다. 가중치 개수가 n개라면 n차원의 평면이 손실 함수가 됩니다. 가중치가 여러 개라면 각각의 w에 대해 편미분하여 극소값을 찾을 수 있겠지만 손실 함수가 최소가 되는 지점이 아니게 됩니다. 따라서 경사하강법을 사용해야 local minimum 값을 찾을 수 있습니다.
그런데 왜 global minimum이 아니라 local minimum 이라는 용어를 썼을까요? 그 이유는 다음 그래프를 보시면 알 수 있습니다.

위의 그래프를 보면 왼쪽 화살표 가장 아래에 있는 곳이 global minimum 입니다. 하지만 시작점의 위치에 따라서 오른쪽 화살표 따라가게 되고, 가장 마지막 지점에서 local minimum을 찾게 됩니다. 즉, 경사하강법은 global minimum을 찾는 방법이 아니라 local minimum을 찾는 방식입니다. 머신 러닝을 할 때 이것을 염두하고 global minimum을 찾기 위해 초매개변수를 잘 변경해줘야 합니다.
'dev' 카테고리의 다른 글
| [코드숨 리액트 강의] 5주차 회고 - 비동기 코드에서 Thunk를 쓰는 이유 (0) | 2022.06.06 |
|---|---|
| "나는 LINE 개발자입니다"를 읽고 (0) | 2021.09.12 |
| React에서 setInterval 제대로 쓰는 방법 (0) | 2021.07.29 |
| AI 이미지 캡셔닝 - Image Captioning (0) | 2020.12.16 |
| 딥러닝 모델의 Overffiting을 줄이는 방법 (0) | 2020.12.15 |




댓글