이 글은 Washington University in St.Louis의 Jeff Heaton 교수님의 강의를 참고하였습니다.
링크 : https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_10_4_captioning.ipynb
딥러닝 학습을 통해 이미지 캡셔닝(Image Captioning)을 하는 방법에 대해 알아보겠습니다.
목차는 다음과 같습니다.
<목차>
1. Image Captioning이란?
2. 전체적인 구조
3. Word Embedding(Glove)
4. 실습 예제
1. Image Captioning이란?

이미지를 설명하는 캡션(설명)을 만들어 내는 것을 의미합니다.
즉 이미지를 입력으로 넣으면 문장이 만들어지는 것으로
이 분야를 AI 에서는 text generation 이라고 합니다.
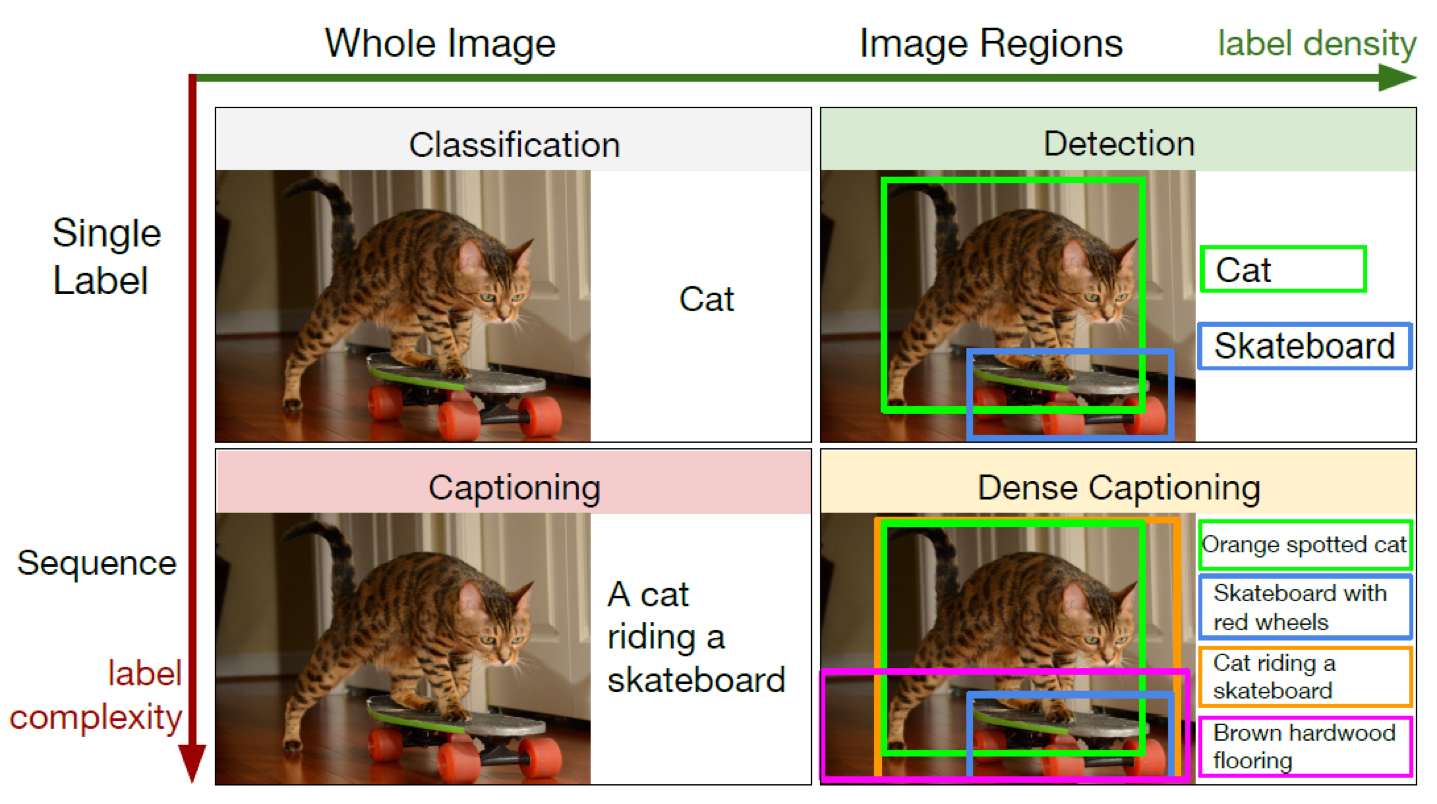
이미지 캡셔닝은 분류(Classification)와 비슷한데요, label density와 label complexity로 Classification, Detection, Captioning, Dense Captioning으로 나눌 수 있습니다. 저희는 이중에 Captioning을 알아보고 있고요.
Image Captiong 의 활용 방법
1. 이미지에 캡션(설명)을 달아서 검색의 질을 높일 수 있습니다.
이미지에 설명까지 있다면 당연히 검색의 효율이 더 좋아질 것입니다.
2. 시각장애인이나 저시력자에게 사진을 설명해줄 수 있습니다.
앞이 잘 안보이는 사람이 카메라로 사진을 찍으면 앞에 무슨 장면이 있는지 알 수 있겠죠!
3. 미술 치료시 치료사의 주관 및 경험을 배제하여 객관적인 미술 치료를 할 수 있습니다.
이건 실제 논문에서 봤던 내용입니다.
논문 링크 : www.earticle.net/Article/A366290
이미지 캡셔닝 대회 1등 모델
2015년 Microsoft Image Captioning 대회에서 구글이 만든 모델이 1등을 차지했습니다.
2014년 11월에 발표한 논문인 "Show and Tell: A Neural Image Caption Generator”을 개선시킨 모델이라고 합니다.
InceptionV3를 쓴다고 합니다.
현재의 Image Captioning
Microsoft에서 훨씬 더 발전한 Image Captioning 모델을 만들었다고 발표했습니다.
Seeing AI assistant app을 업데이트하여 MS 워드, 파워포인트, 아웃룩 등에서 사용할 수 있게 하였다고 합니다.
MS office 프로그램으로 사진에 대한 설명을 자동으로 달아주면 굉장히 편리할 것 같네요.
마소왈, 2015년 모델보다 2배 더 좋은 모델이라고 합니다.
관련 링크 : blogs.microsoft.com/ai/azure-image-captioning/
What’s that? Microsoft’s latest breakthrough, now in Azure AI, describes images as well as people do - The AI Blog
Novel object captioning Image captioning is a core challenge in the discipline of computer vision, one that requires an AI system to understand and describe the salient content, or action, in an image, explained Lijuan Wang, a principal research manager in
blogs.microsoft.com

구글의 이 좋은 이미지 캡셔닝 모델을 저도 사용할 수 있는가 찾아보니 Azure AI에서 사용할 수 있다고 하는데요

Azure는 사용하려면 비용을 지불해야 해요 ㅠㅠ
Image Captioning의 원리 및 구조

이 사진을 설명하는 글을 어떻게 만들 수 있을까요?

이런식으로 사진에 어떤 object가 있는지 알 수 있고, object들을 통해 설명(캡션)을 만들 수 있지 않을까요?
예를 들어 위의 사진에서 골키퍼, 공격수, 골대, 축구공, 손흥민(?)을 찾아내서
"손흥민이 골키퍼의 수비를 피해 골대 안으로 축구공을 슈팅하고 있다."
이런식으로 말이죠!

하지만 실제로 Image Captioning에서는 사진에서 "골키퍼, 공격수, 골대..." 등과 같은 물체가 무엇인지를 추출하진 않습니다. 왜냐하면 우리가 하고 싶은 건 Object Detection이 아니라 Image Captioning 이니까요.
위의 그림은 구글에서 만든 InceptionV3 모델의 구조입니다.
InceptionV3는 1000가지 물체를 구분할 수 있는 모델로 2014년 IRSVRC(이미지 분류 대회) 대회에서 1등을한 InceptionV1으로 부터 보완된 모델입니다.
InceptionV3에서 마지막 단(FC)을 없애면 2048개의 feature 들이 나오는데요, 이를 이용해서 이미지 캡셔닝을 할 수 있습니다.

encode_model.summary() 함수를 이용하면 코드에서 불러온 InceptionV3의 구조를 확인할 수 있는데요
마지막 단에 2048개의 feature가 나온다는 걸 알 수 있습니다.
결국 우리는 사진을 2048개의 feature로 추출하여 이미지 캡셔닝에 사용할 수 있습니다.
추출한 feature로 캡션(설명) 만들기

위에서 설명드렸다시피 우리는 InceptionV3에서 마지막 출력단을 삭제합니다.

그리고 이것을 RNN, 여기서는 LSTM을 활용해 문장을 만들게 됩니다.

RNN을 사용하는 방법은 여러가지가 있는데 그 중에 하나가 LSTM 입니다.
RNN은 쉽게 설명드리면 기존 뉴럴 네트워크와 다르게 '기억'을 할 수 있고, 이 특징 때문에 text generation에 RNN을 사용합니다. 기억이라는 특징이 문장을 만드는 것과 무슨 상관이 있을까요?
"I love" 라는 문장 뒤에 단어를 하나 붙여서 문장을 완성한다고 생각해봅시다.
뉴럴 네트워크 모델이 I, love라는 단어가 있다는 걸 기억하고 있다면
그다음에 올 단어가 명사라는 걸 쉽게 알 수 있겠죠?
그렇기 때문에 text generation은 RNN을 사용합니다.

전체적인 구조는 위와 같습니다.
우리가 학습하는 건 LSTM이고요, InceptionV3 즉 CNN은 이미지 인코더에 불과하다는 걸 알 수 있습니다.

위의 예시를 보시면, (강아지 사진 + a dog)가 Neural Network의 Input으로 들어오면 runs일 확률이 가장 높기 때문에 runs 라는 단어를 추가하여 a dog runs 라는 문장을 만들게 됩니다.
즉 학습을 통해 위의 Neural Network를 만들게 되는 것이죠.
워드 임베딩이란?

위의 구조에서 보시면 Wemb 즉, Work Embedding 이란 걸 보실 수 있습니다.
이 워드 임베딩이란 무엇일까요?
사람의 단어는 유사도가 있습니다.
예를 들어 man과 king은 유사도가 높고, man과 queen은 유사도가 낮습니다.
LSTM에 단어를 넣을 때 유사도를 표현하지 않고 넣을 수도 있지만
워드 임베딩을 이용해 단어와 단어의 유사도 정보를 함께 넣어준다면
AI는 더 좋은 문장을 만들 수 있을 것입니다.
워드 임베딩을 쓰는 두번째로는 학습하지 않은 단어도 더 잘 예측할 수 있게 됩니다.
영화평에 대한 문장을 보고 긍정적/부정적인 평인지 판단하는 AI를 만든다고 생각해보겠습니다.
It is good movie를 positive로 학습했다면
This is best show를 positive로 예측하기가 쉽게됩니다.
이에 대한 쉽고 자세한 설명은 허민석씨의 유튜브 자료를 추천드립니다.
링크 : https://www.youtube.com/watch?v=sY4YyacSsLc
예제
예제 링크 : https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_10_4_captioning.ipynb

예제에서는 Flicker8K 데이터셋, CNN은 InceptionV3, RNN은 LSTM, 워드 임베딩은 Glove를 사용합니다.

flickr는 야후의 사진 공유 웹 사이트인데요,
Fliicker8K 데이터셋은 이 사이트의 8000개 사진에 대한 설명(캡션)을 가지고 있는 데이터셋입니다.
데이터셋에 있는 예시를 하나 살펴보겠습니다.

1000268201_693b08cb0e.jpg#0 A child in a pink dress is climbing up a set of stairs in an entry way .
1000268201_693b08cb0e.jpg#1 A girl going into a wooden building .
1000268201_693b08cb0e.jpg#2 A little girl climbing into a wooden playhouse .
1000268201_693b08cb0e.jpg#3 A little girl climbing the stairs to her playhouse .
1000268201_693b08cb0e.jpg#4 A little girl in a pink dress going into a wooden cabin .
위의 사진 하나에 대해서 5개의 캡션이 있습니다.

Glove 워드 임베딩도 pre-trained 된 워드 벡터(유사도를 이용해 단어를 벡터로 표현한 것)를 받아서 사용합니다.

Glove 임베딩에서 the를 열어보니 하나의 단어를 200개의 숫자로 표현한 걸 알 수 있네요.
예제 코드를 실행해본 결과 저는 이미지 캡셔닝 결과가 별로 좋지 않더군요.
여러분들도 예제 한번씩 실행해 보시면서 (코랩에서 바로 실행 가능합니다.)
결과가 잘 나오는지 해보시면 좋을 것 같습니다.
'dev' 카테고리의 다른 글
| [코드숨 리액트 강의] 5주차 회고 - 비동기 코드에서 Thunk를 쓰는 이유 (0) | 2022.06.06 |
|---|---|
| "나는 LINE 개발자입니다"를 읽고 (0) | 2021.09.12 |
| React에서 setInterval 제대로 쓰는 방법 (0) | 2021.07.29 |
| 딥러닝 모델의 Overffiting을 줄이는 방법 (0) | 2020.12.15 |
| 머신 러닝 첫 걸음 (1) | 2020.12.15 |




댓글